语言模型的概念
给定一列单词,语言模型的任务是预测下一个可能出现的单词的概率分布:
从另一个角度讲,语言模型可以给出一段文字的概率。因为:
语言模型的实现
1. n-gram Language Model
n-gram Language Model 是一种最简单的语言模型。它只通过每个单词的前个单词来预测该单词,即将单词预测简化为一个马尔可夫过程,进而通过条件概率公式使用频率预测概率:
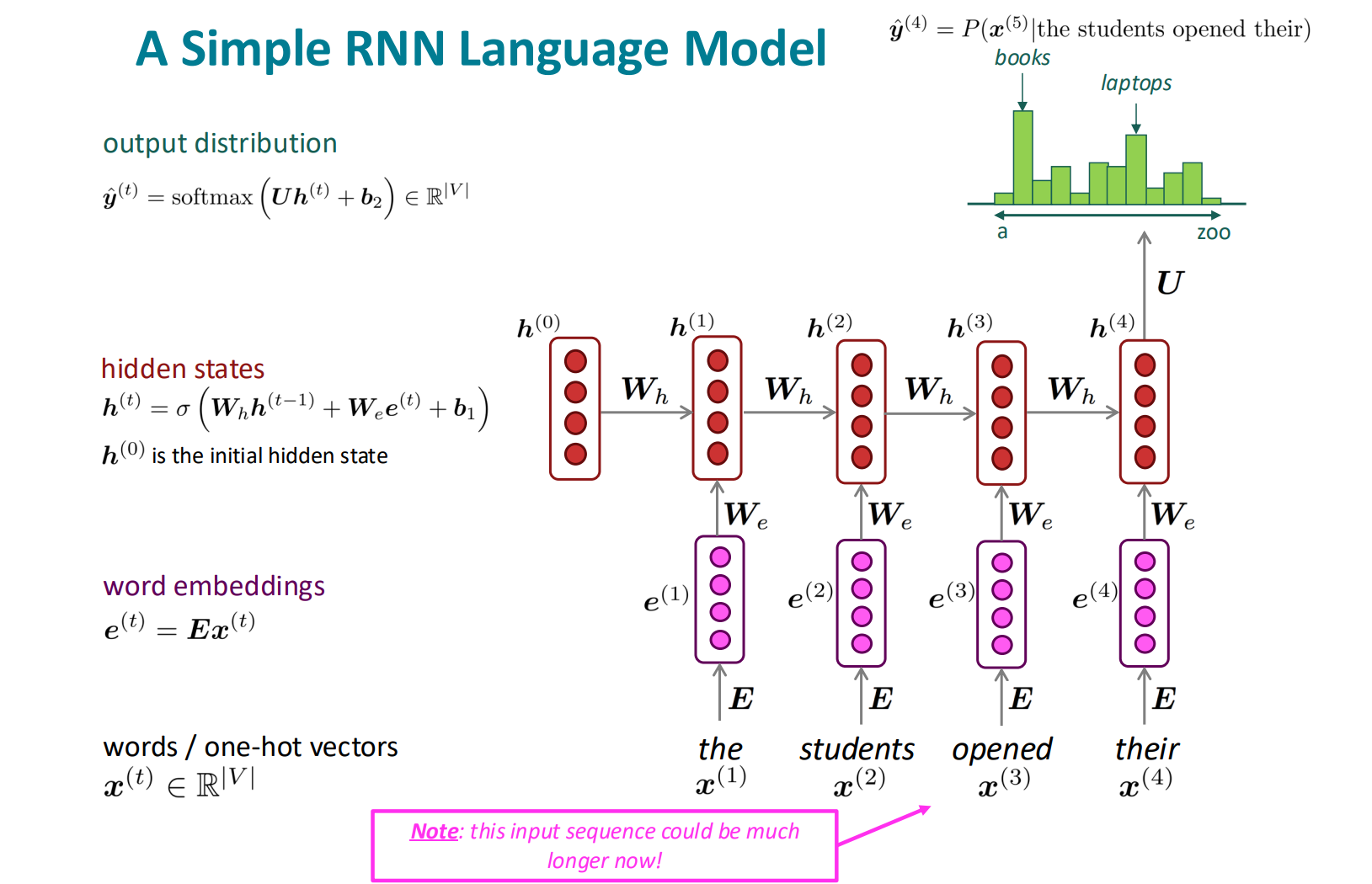
2. Recurrent Neural Networks (RNN)
n-gram Language Model 的马尔可夫假设严重地限制了模型的语义理解能力,因此我们需要构造一种可以输入文本任意长,关键词在不同位置出现都等价的语言模型。
梯度消失与梯度爆炸
在上述的向前传播过程中,每一位置的单词预测都会产生误差。设模型预测分布为,实际分布为 (one-hot),使用交叉信息熵衡量误差:
模型在一个单词序列上的平均误差为:
考虑模型的反向传播,在计算的时候,需要层层计算到最初的层,再将每一层的梯度求和:
这在传播链路过长(单词序列过长)的时候会出现问题,如 (为简化计算,假设不套用非线性的sigmoid函数):
可以观察到出现了的高次方项。即若的特征值小于1, 则梯度会呈次方衰减,称为梯度消失;若大于1,则梯度会呈次方增长,称为梯度爆炸
- 梯度消失会导致来自远处单词的梯度难以传递到当前单词,即模型“遗忘的速度过快”,通常有效的传播长度只有7个单词左右。
- 梯度爆炸会导致模型难以收敛
处理梯度爆炸——gradient clipping
如果得到的梯度太大,则将其缩放到长度阈值。
处理梯度消失——Long Short-Term Memory RNNs (LSTM)
在原有的RNN基础上加上记忆层 (Cell Layer, c),并通过门 (gates) 来控制记忆的存留,更新与使用。
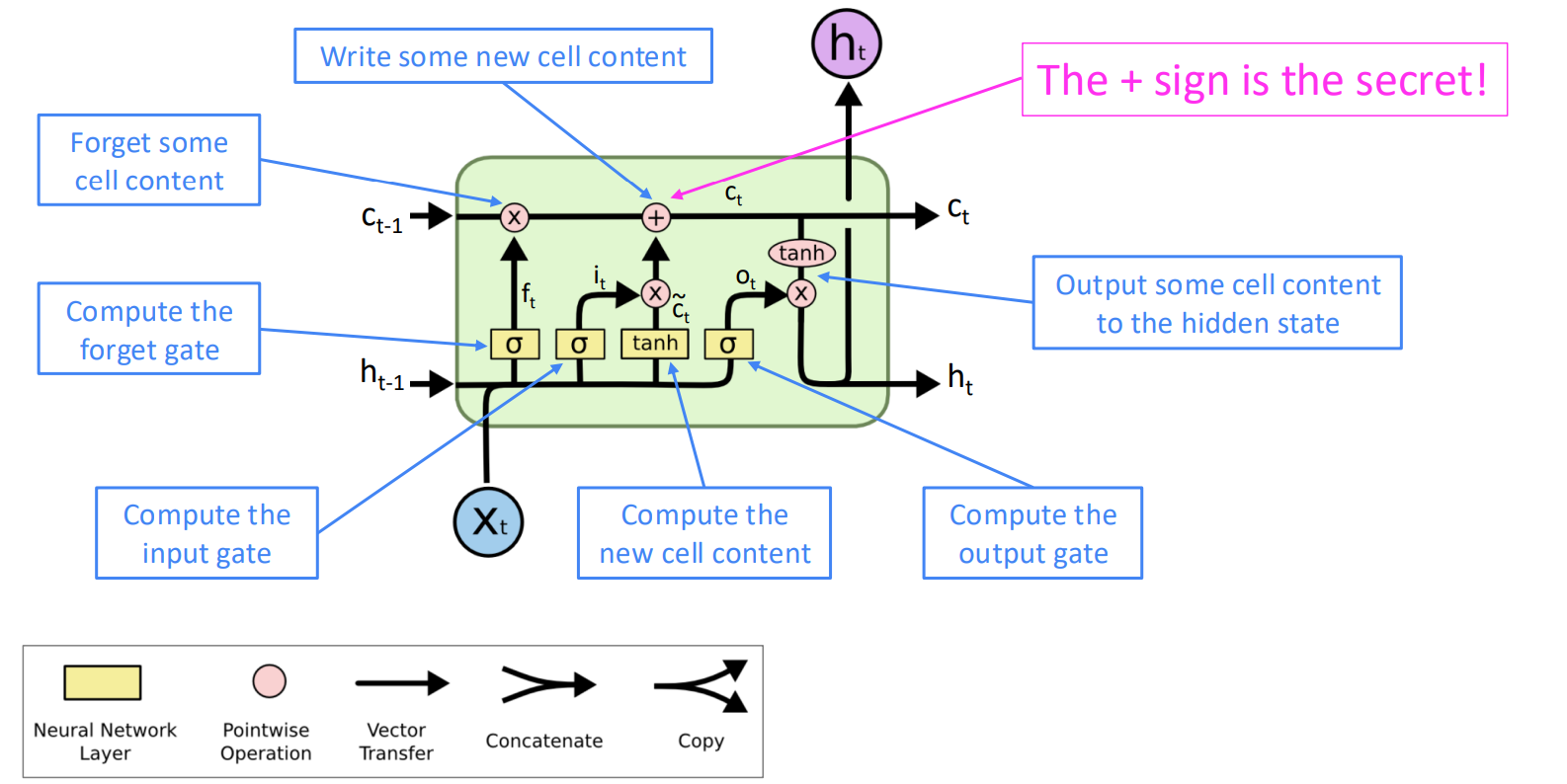
- forget gate (f):控制上一次的记忆有多少被存留
- input gate (i):控制新的记忆有多少被写入
- output gate (o):控制有多少记忆被用于预测当前单词
对于每一个输入单词,更新流程如下:
- 产生新的记忆
- 根据新的记忆更新原有记忆
- 根据更新后的记忆产生当前输出
- 之后按照RNN的方式处理即可
LSTM模型在经过一些优化之后,被成功应用于神经机器翻译领域