问题抽象
给定一个单词表。其中词语构成的一个n长序列表示为 (其中每一个词语用长的独热码表达)。
一个语言模型的任务是使用前个词语去预测第个位置的词语:
问题的关键在于确定一个映射,将长的独热码序列转换成单词表中每个单词的得分。最后再通过函数将得分转换为概率即可。
词嵌入
首先需要将独热码编码的单词转化为有语义的向量,称为词嵌入 (Word Embedding)。
上下文无关词嵌入
上下文无关词嵌入是基本的词嵌入手段,即将每个单词视作独立的个体,用向量表示其内禀的含义,记为向量。
设词向量的维度为,则词嵌入矩阵为。记上下文无关词嵌入得到的词向量序列为,则有:
上下文相关词嵌入
上下文无关词嵌入只能得到每个单词独立的含义,却不能得到单词放在特定语境 (单词序列) 下的含义。上下文相关词嵌入就是在上下文无关词嵌入的基础上,得到单词在特定语境下的含义,表示为向量
思路一、使用RNN
传统的做法是使用RNN语言模型的中间态作为编码:
但是RNN的缺陷在于:
- 数据间的序列相关性 (如要计算,必须先计算) 无法高效利用GPU的并行计算速度优势。
- 序列间大量的矩阵操作使得模型的“遗忘速度”过快,无法很好地理解相距较远的上下文。
思路二、使用自注意力机制 (self-attention)
注意力机制很早之前便被提出,并且应用在神经机器翻译等领域优化使用RNN模型的decoder-encoder架构。此时的注意力机制为cross-attention:基于一个输入序列生成另一个输出序列
在此基础上稍作调整,便得到了自注意力机制 (self-attention):根据输入序列,预测输出。
1. 自注意力的工作原理与K-Q-V矩阵
- 根据当前词向量,得到query向量
- 对于序列的每一个单词,计算得到其key和value向量
- 根据key向量和query向量计算得到序列的每个单词与当前词的注意力得分,并通过函数归一化
- 根据序列各个单词的得分对values向量组加权平均,得到
2. 位置信息的表示
上述的自注意力机制虽然解决了RNN的两个缺陷,但是却出现了新的问题——舍弃序列模型后,单词在序列中的位置信息无法表达。
一个之际的解决方式就是修改单词向量,在其中插入位置信息。设最大序列长度为,则位置信息为。将其加入词向量中得到包含位置信息的词向量:
3. 多层注意力
如果需要使用多层注意力,那么直接将第一层的输出作为第二层的输入是不够的,因为中间缺少非线性变换,导致最终的效果等价于单层注意力。
因此,要在层与层之间加入非线性变换层(feed-forward network):
一般取使中间层的维度大于,如取,。
Transformer架构
在上文提及的基于自注意力机制的上下文相关词嵌入基础上,可以使用Tranformer架构构建起完整的语言模型
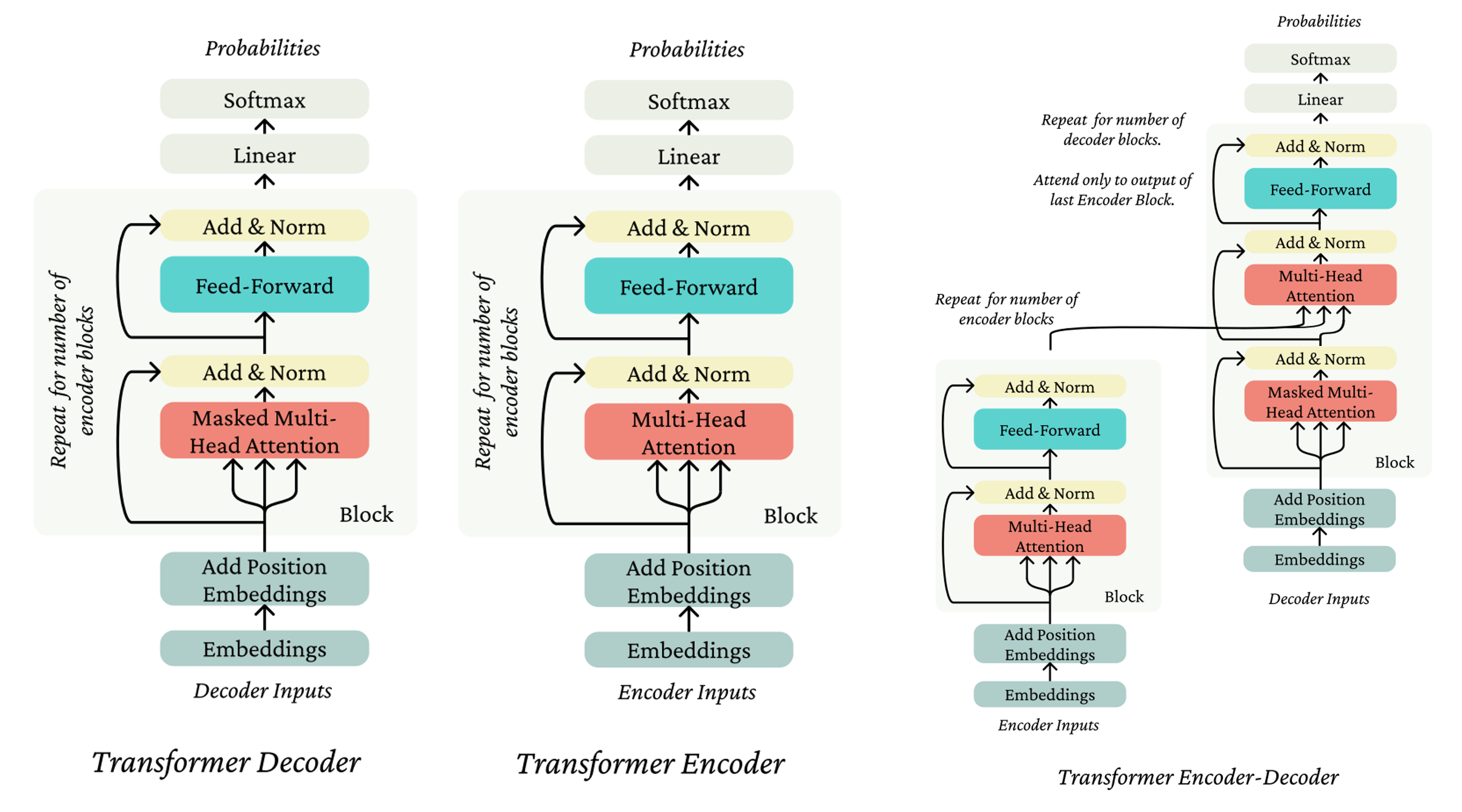
Transformer Encoder 和 Decoder 的区别
- Encoder 的self-attention机制中没有future mask,即任何一个单词都可以看到其后出现的单词,更适用于语义理解
- Decoder 的self-attention机制中存在future mask,即所有单词均只能看到前面出现的单词,更适用于语言生成
实际应用中大量的Transformer均只是decoder-only的
多头注意力机制 (Multi-head Self-Attention)
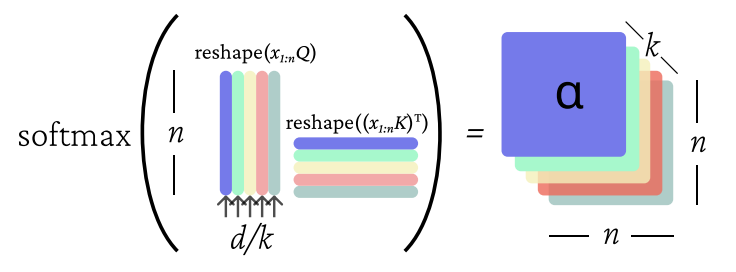
设需要构建头注意力,则需要个独立的K,Q,V矩阵。为了避免多头注意力带来额外的计算开销,将原来的词向量降维到维即可。
具体的,,对于每一个注意力头:
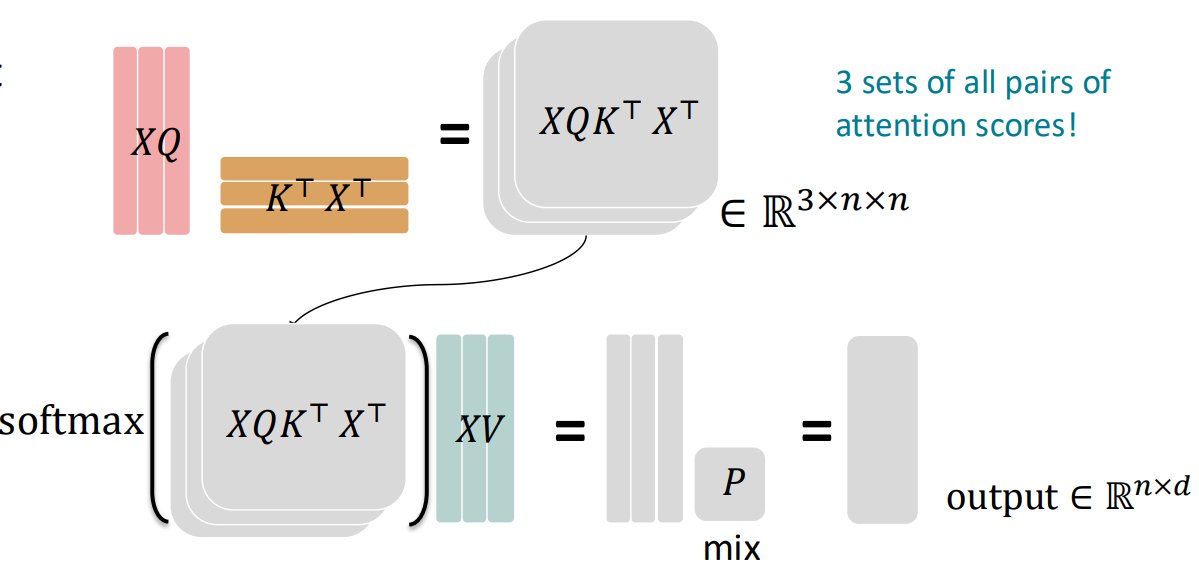
最后将每个注意力头输出的拼接起来并经过线性变换,即可得到总。 也可以通过矩阵运算将多个注意力头叠加计算,提高效率:
层标准化 (Layer Normalization)
层归一化可以减少一层输出中被无效激活的神经元数量,且可以提高梯度下降的效果。步骤如下:
- 计算每一个输出向量的参数平均值与方差
- 对每一个输出向量做标准化
残差连接 (Residual Connections)
残差连接可以起到稳定梯度的作用,防止梯度消失
训练流程
Step 1、预训练 (Pretrain)
在传统的训练中,所有除了词嵌入以外的模型的参数都是随机初始化的,这会影响模型的表现。预训练就是使用恰当的手段训练模型的全部参数,使得模型在初始时不仅能够理解单词本身的含义 (预训练的词嵌入矩阵),也能理解单词在语境中的含义 (Transformer中的参数),即语言整体。
预训练的思路如下:输入为大量的文本,每次中文本中剔除掉一个单词让模型预测,被剔除的单词就可以作为标签计算预测的损失函数。经过预训练,模型就大致“学会了”这个语言
Step 2、微调 (Finetune)
现在我们已经有了一个学会了整个语言的大模型,微调就是让大模型在此基础上学习特定的任务,如情感分析等。
在这一步中,我们需要提供一些有标签的数据进行监督学习