encoder-decoder架构 与 Seq2seq模型
- encoder-decoder架构:使用一个语言模型对输入编码,并衔接另一个语言模型对编码解码。
- Seq2seq模型:输入一个序列,输出另一个序列
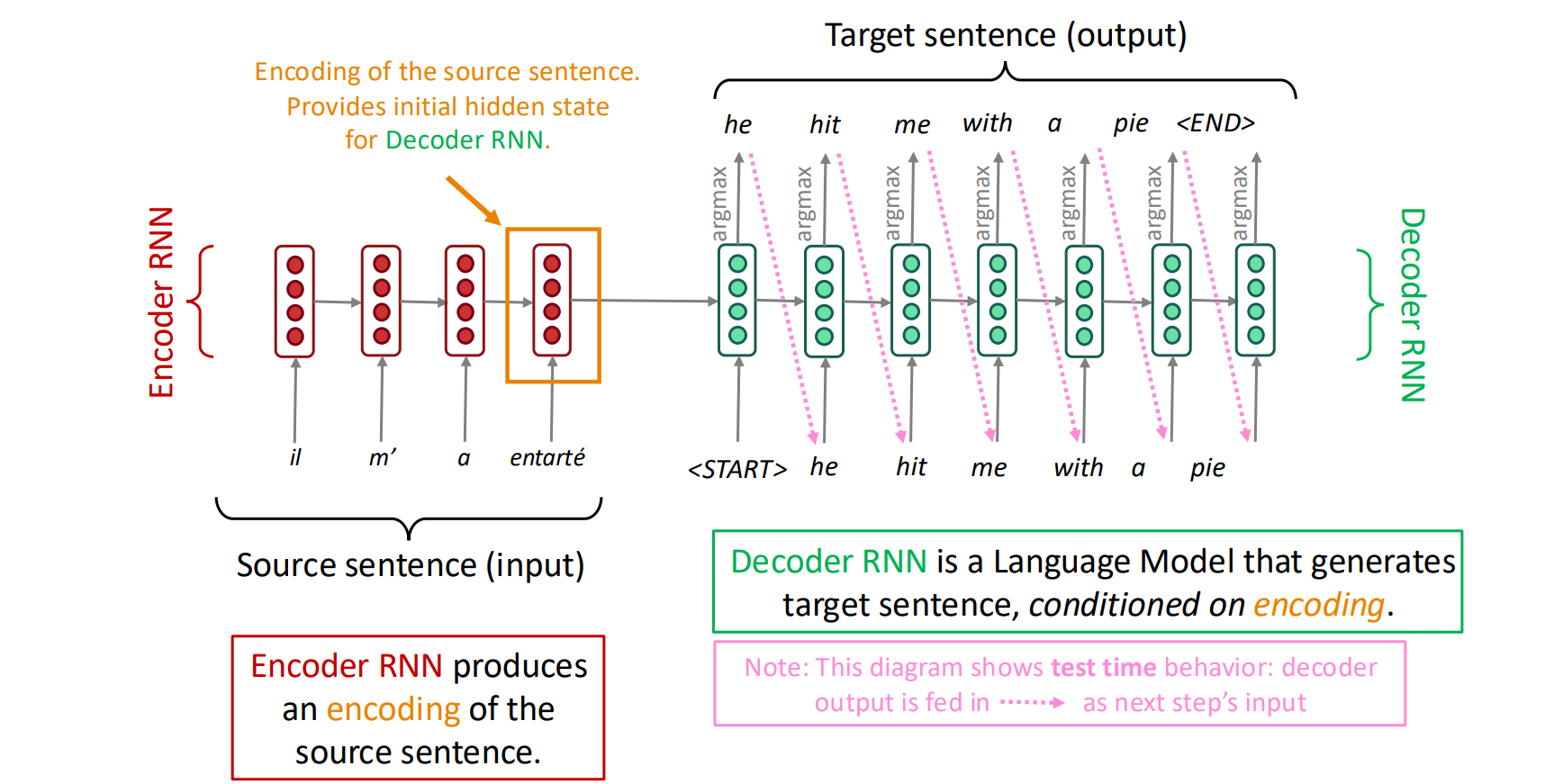
使用encoder-decoder架构的Seq2seq模型可以被应用于神经机器翻译领域:输入为一个语言的文字序列,输出为另一个语言的对应翻译序列。
在传统的LSTM基础上,使用一个LSTM对输入编码,并衔接另一个LSTM对编码解码。
注意力机制 (Attention)
给定一个向量集合values,和一个query向量。注意力机制帮忙根据query向量计算出values的一个加权平均
以神经机器翻译为例,上文给出了处理该问题的模型
这个架构存在巨大的缺陷:解码模型所依赖的输入仅仅是编码模型的最后一个隐藏状态,即编码模型需要把对于句子的理解全部输入进入最后一个状态,并指导解码的全过程。这不符合人类的翻译过程,在翻译到特定的位置时,我们需要回头去看对应位置的原文,即需要有一个动态变化的注意力机制,在解码模型翻译时,可以动态地参考编码模型的关键中间隐藏状态。
在这里,values是编码LSTM的隐藏向量集,query是解码LSTM的一个隐藏向量。
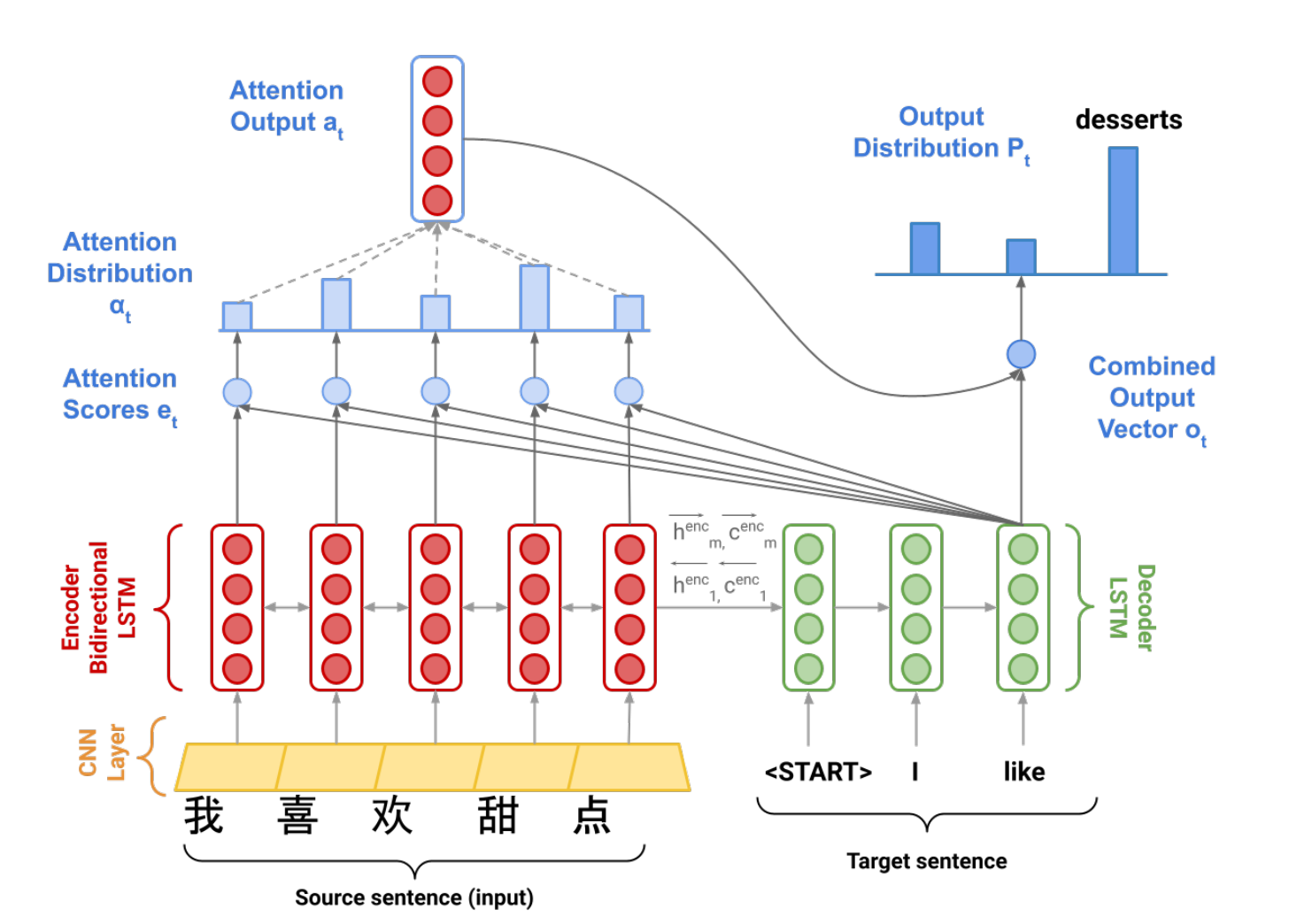
设编码模型的中间状态为,解码模型的中间状态为,其余变量定义如图
- 每翻译一个词,剩余的语义就需要更新 (对应解码模型输出更新隐藏状态)
- 根据更新后的语义,回头挑出原句子中重要的部分 (根据解码模型的隐藏状态去给每一个编码模型的每一个中间隐藏状态打分,并处理得到按注意力分布加权平均的编码模型中间态)
计算attention scores的方法
除了上面使用的直接点乘的方法之外,还可以:
- 在中间加入变换矩阵 (bilinear attention):
- 中间插入变换矩阵的降维版本 (Reduced-rank multiplicative attention):
- 使用一层小型的神经网络 (additive attention):
- 结合更新后的语义与此时原句的注意力分布,得到一个新的词输出