区分训练集,交叉验证集,测试集
- 训练集:数据用来训练模型。最终的代价函数要足够小,以防止欠拟合
- 交叉验证集:确定训练中的最优参数。如回归模型中预测函数的次数;正则化过程中选取的参数。通常选择一系列参数进行训练,从同挑选代价函数最小的,以防止过拟合与欠拟合
- 测试集:测试最终确定的模型以及参数的效果
使用学习曲线 (Learning Curves) 进行合理检验 (sanity check)
随着训练样本的增加,模型将不能很好地适应训练样本,但是却能更好的预测交叉验证集与测试集
- 在欠拟合请情况下,增加并不能继续减小训练集与交叉验证集的误差差距。此时的训练已经达到模型的最佳效果:
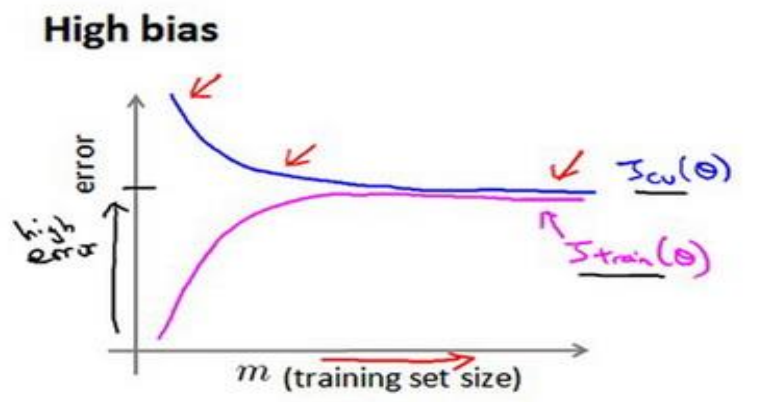
此时可以考虑增加更多的特征,采用更负责的模型,减小正则化参数等等
- 在过拟合的情况下,增加可以继续减小训练集与价差验证集的误差差距
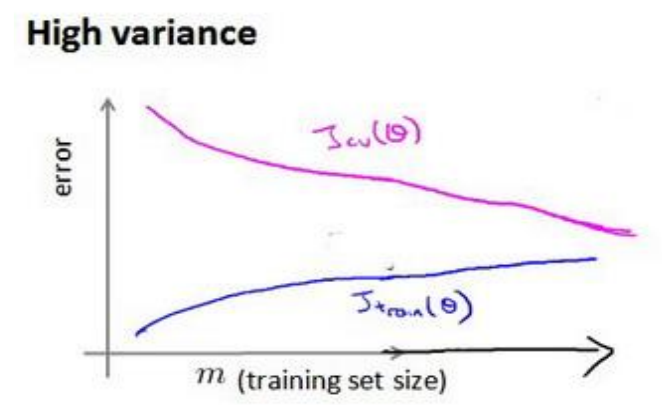
此时可以考虑增加更多训练实例,简化模型,增加正则化参数等等
误差分析
人工检查交叉验证集中预测错误的实例,观察是否具有系统性倾向
误差指标的构建——考虑类偏斜
类偏斜是指训练集中充斥着大量的属于同一类的实例,这个时候再使用预测的准确度衡量误差的话,就会导致模型向作出该类预测的方向偏斜
解决办法为设置更加科学的指标:正确肯定 (True Positive),正确否定 (True Negative),错误肯定(False Positive),错误否定 (False Negative)
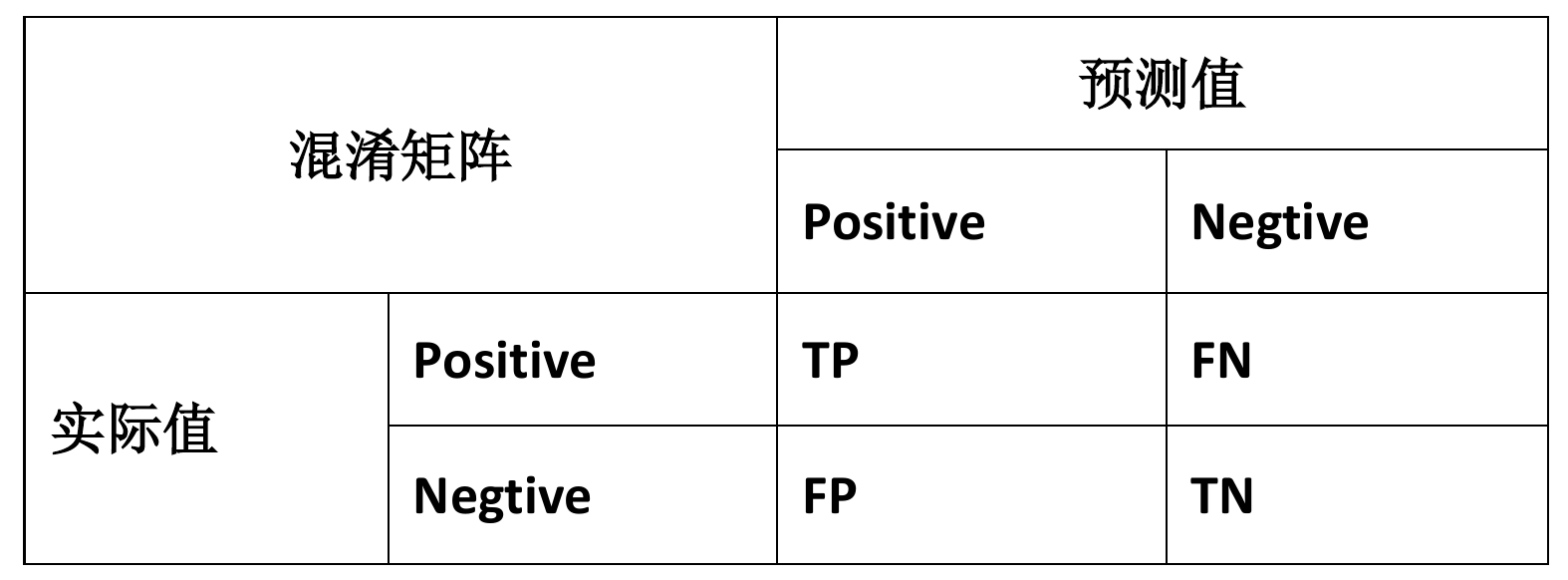
- 查准率 (Precision):作出预测后,预测的准确率。
- 查全率 (Recall):对于属于该类的实例,模型成功预测的概率。
一般的sigmoid函数分类问题中,采用0.5作为01判定的阈值。若想提高查准率,则可提高阈值;若想提高查全率,则可降低阈值。 普通情况下,我们希望平衡查准率和查全率,则可考虑F1值:
根据最大化F1值的目标确定阈值